新京报贝壳财经讯(记者白金蕾 韦英姿 罗亦丹)7月3日下午,在新京报贝壳财经夏季年会“‘通’往未来 向新有AI”主题论坛上,新京报贝壳财经联合北京智源研究院、中国经济传媒协会发布行业首份《中国AI大模型测评报告——公众及传媒行业大模型使用与满足研究》(下称:报告)。本次报告特色内容为新京报人工智能研究院自行研发的针对大模型传媒能力的测评体系。
测评选取了较为知名的9款大模型应用程序(或其网页版),分别考察了其文本生成能力、事实核查与价值观判断能力、媒体信息检索能力、翻译能力以及长文本总结能力,旨在评估不同大模型助手针对媒体行业实际工作场景的能力表现,并形成最终排名。
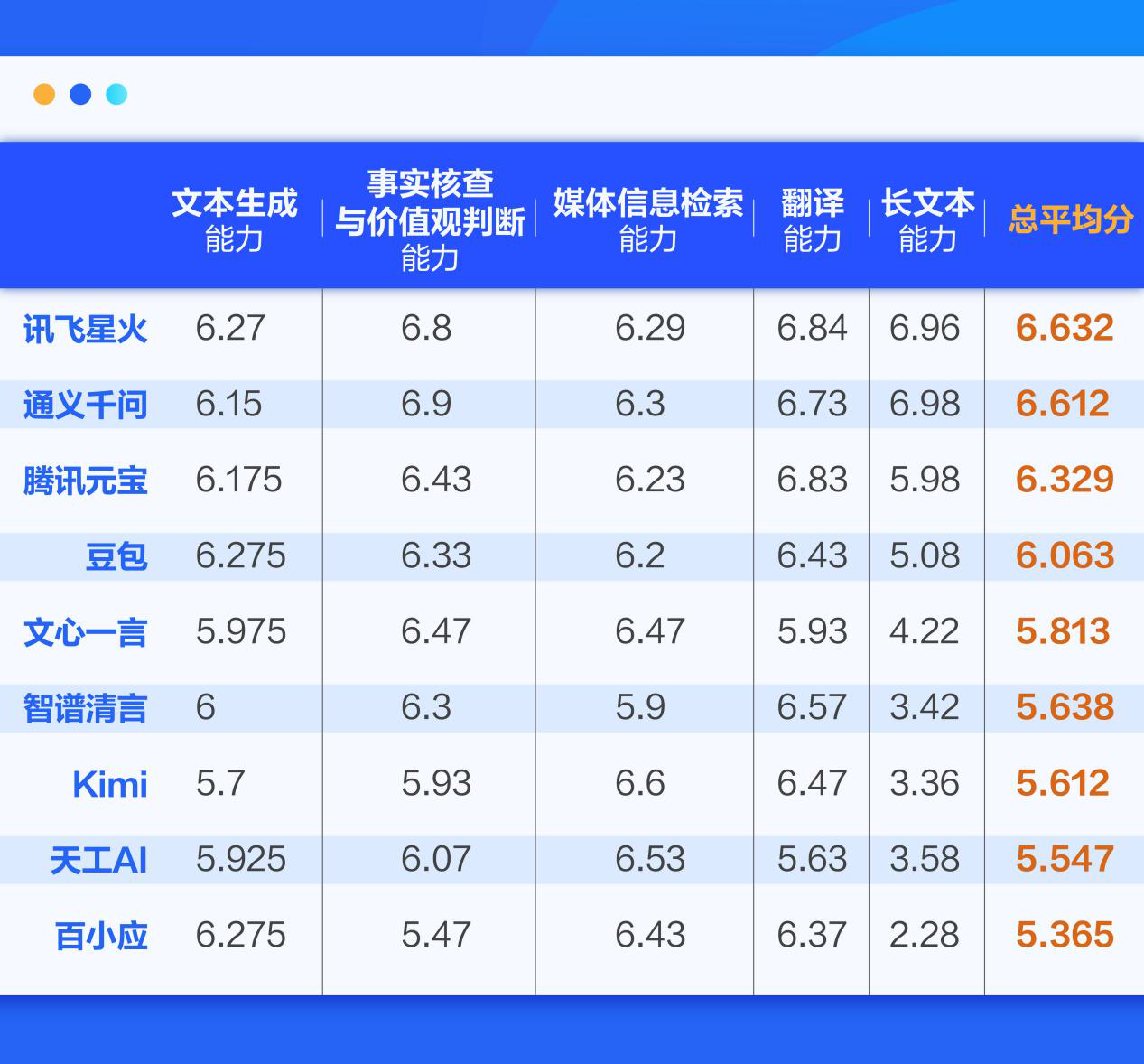
在总体得分上,通义千问、腾讯元宝、讯飞星火夺得前三名,主要是这三个模型在此次评测的五大维度上均没有明显短板。其中,通义千问在事实核查与价值观判断能力、长文本能力上均排名榜首,讯飞星火则在翻译能力上排名第一,且综合能力最强。
横向对比大模型五个维度的平均得分水平,翻译能力得分6.42,排名第一。事实核查与价值观判断能力以及媒体信息检索能力得分6.3,并列第二。第四是文本生成能力,得分6.08,最后是长文本能力,得分4.65。
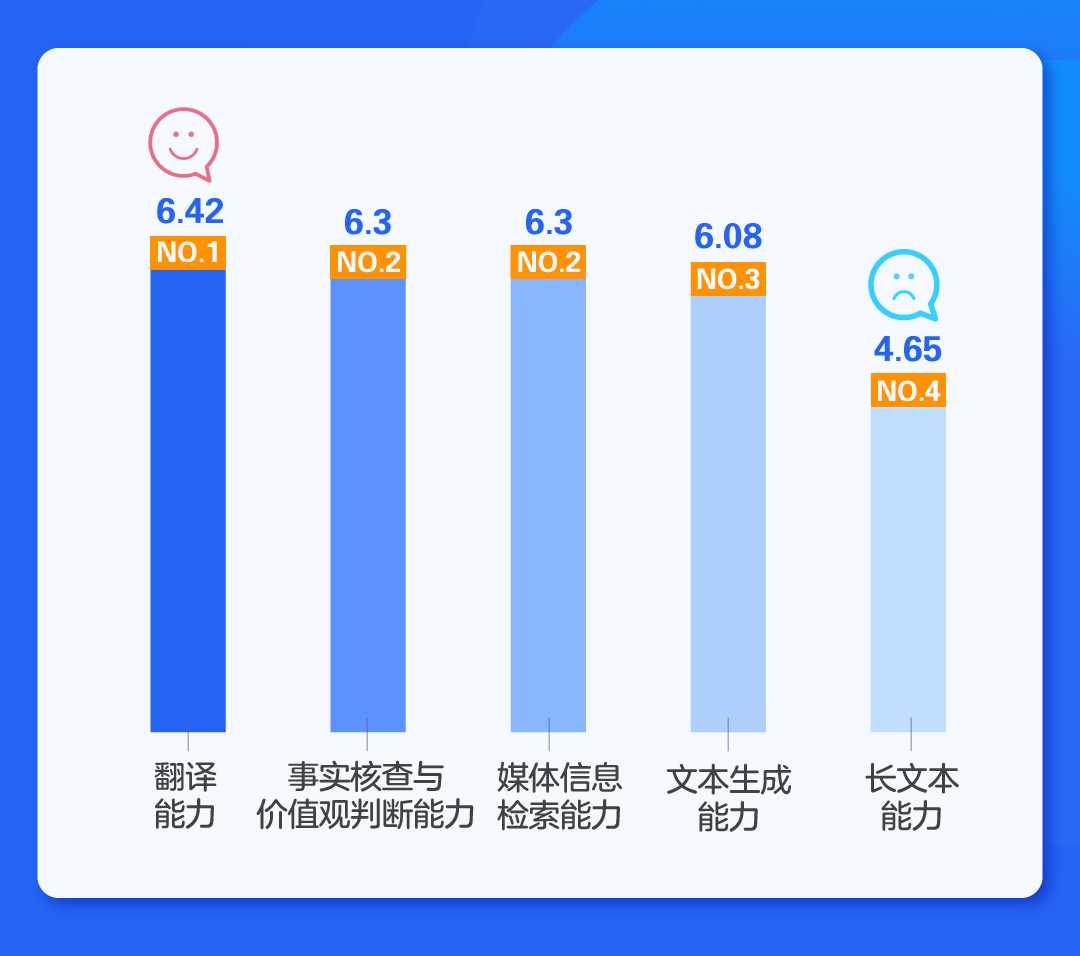
由此可见,媒体从业者对于使用大模型进行翻译工作较为满意,而通过大模型联网总结热点事件也较为准确,大模型的价值观未见明显问题。与新闻写作相关的文本生成则处于“可用”状态。总体来看,上述四项维度的功能均处于“及格线”以上,根据测评人员的反馈,大模型生成的新闻稿虽然可用但相比人类仍稍逊一筹,相比之下,大模型的翻译能力、检索总结新闻能力以及其价值观判断能力已经得到了部分测评人员的认可。
此外,对于大模型从长文本中“大海捞针”找关键点的能力,大部分大模型仍然无法胜任。特别是给出1-999个顺序排列的数字,寻找其中两个顺序颠倒的数字这一测试,9款大模型除了通义千问给出了2个答案(一对一错)外,其余8款大模型“全军覆没”,说明大模型仍有缺陷之处。
编辑 王进雨
校对 杨利








