当硅谷仍在为GPU万卡集群豪掷千亿资金时,来自杭州的一群年轻人用557.6万美元证明:AI大模型的比拼或许并不只靠规模,而是要看使用效率。只要技术实力足够强,一款上架不足半个月的App也能击败ChatGPT,在1月27日登顶苹果应用商店排行榜。
这几天,AI圈最火的大语言模型,不是ChatGPT,不是文心一言,甚至不是国内“AI六小虎”中的任意一个,而是杭州AI公司深度求索所推出的DeepSeek。从去年12月26日发布的DeepSeek-V3,到1月20日发布的DeepSeek-R1,这家公司以OpenAI三十分之一的API价格,实现了在多项测试中表现持平甚至超越OpenAI的o1模型(下称o1模型)的成绩,给美国AI行业人士带来了中国大模型“花小钱办大事”的冲击。
新京报贝壳财经记者对此进行了实测,经过同题问答发现,DeepSeek-R1的“深度思考”模式以步步推理的方式生成了具有逻辑性的回答,用户还能看到思考过程。
“这种惊喜和第一次用ChatGPT3.5差不多,甚至感觉更震撼。ChatGPT写套路性很强的应用文很好用,但一旦涉及高语境,调侃,讽刺,就有浓浓的AI味,没有幽默感。DeepSeek对高语境内容和中文网络上的梗都能理解明白,内容基本达到了脱口秀文本的水平。”1月27日,IT从业者刘鸿博告诉贝壳财经记者。
低成本比肩OpenAI o1模型 硅谷“烧钱模式”遭质疑
“你能想象一个筹集了10亿美元的‘前沿’实验室,现在却因为比不过DeepSeek而无法发布最新的模型吗?”DeepSeek-R1面世后的第二天,知名文生图大模型Stable Diffusion创始人Emad就对硅谷同行们发出了这样的“灵魂拷问”。
过去几天,面对“横空出世”的DeepSeek,不止一名美国AI从业者开始在社交平台抒发自己内心深处受到的震撼。OpenAI等美国大模型公司一直通过性能领先筑起自己的“护城河”,以此抵御低价竞争者,但面对一款成本仅为“零头”但性能同样优秀的大模型,许多人发现这一叙事已经无法阻止用户“用脚投票”。
北京时间1月27日,DeepSeek在苹果App Store美国区免费应用下载榜上超越ChatGPT,排名第一,在中国区排行榜上同样登顶。此外,DeepSeek在App Store英国区免费应用下载榜的排名升至第二,仅次于ChatGPT,而该App在1月15日才刚刚发布。DeepSeek的出圈如同“TikTok难民”涌入小红书一样,先由国外用户发起。不少用户在社交平台晒出了自己使用DeepSeek的心得,认为这个应用“非常酷”。
根据DeepSeek官方公布的性能测试,该大模型在数学测试、编程等多个领域与o1模型表现“旗鼓相当”,其中MATH-500(评估大模型数学能力)、SWE-bench Verified(评估大模型的软件工程能力)、美国数学邀请赛的测试分数还超过了o1模型。新京报贝壳财经记者测试发现,对于普通的问答问题,DeepSeek的表现同样可圈可点,尤其是自带的“深度思考”模式可以让用户清晰了解到其思考过程。
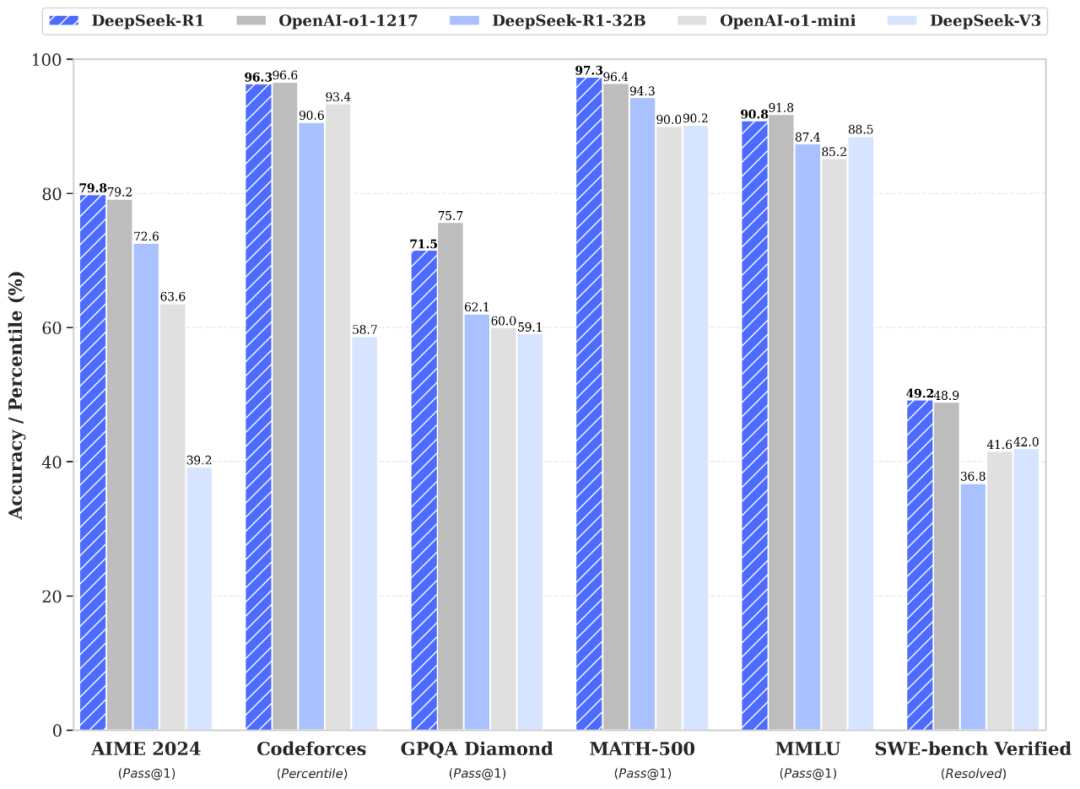
DeepSeek-R1模型技术报告 来源:DeepSeek官网
除此之外,DeepSeek的训练成本还更低,根据其公布的技术文档,DeepSeek-V3模型的训练成本为557.6万美元,训练使用的是算力受到限制的英伟达H800 GPU集群。相比之下,同样是开源模型的Meta旗下Llama3.1 405B模型的训练成本超过6000万美元,而OpenAI的GPT-4o模型的训练成本为1亿美元,且使用的是性能更加优异的英伟达H100 GPU集群。
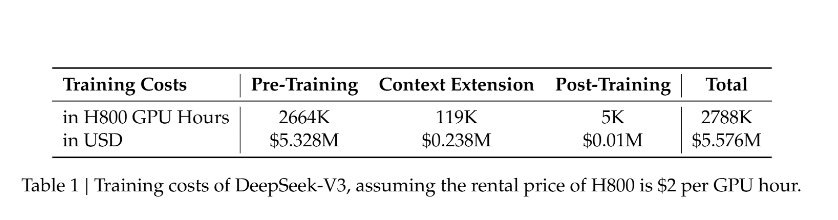
DeepSeek技术文档截图 来源:DeepSeek官网
虽然DeepSeek-R1模型的训练成本并未公开,但从其API价格上也可以感受到“便宜”二字,它的定价甚至连OpenAI定价的零头都不到。DeepSeek-R1的API服务定价为每百万输入tokens1元(缓存命中)/ 4元(缓存未命中),每百万输出tokens16元,而o1模型上述三项服务的定价分别为55元、110元、438元。
事实上,价格便宜早在这次“出圈”前就是DeepSeek的标签。去年年中,国内AI大模型大打“价格战”时,第一个“挑起战火”的正是DeepSeek发布的第二代MoE大模型,但由于彼时DeepSeek并不属于“AI六小虎”之一,其降价声势很快被紧跟其后宣布降价的阿里云、百度、科大讯飞等大厂盖过。
现在,“小透明”不再低调,因为除了价格优势外,其还有足以比肩o1的性能。1月27日,社交平台认证为“AI投资机构Menlo Ventures负责人”的Deedy对比谷歌Gemini和DeepSeek-R1后表示,DeepSeek-R1更便宜、上下文更长、推理性能更佳。
这可能带来更加深远的影响,一位Meta工程师称其内部因DeepSeek进入“恐慌模式”,Scale AI创始人Alexander Wang评价DeepSeek是“中国科技界带给美国的苦涩教训”,证明“低成本、高效率”的研发模式可能颠覆硅谷巨头的高投入路径。社交平台认证为“风险投资人”的ShortBear评论称,“DeepSeek的兴起对那些商业模式为销售大量GPU(英伟达)或购买大量GPU(OpenAI、微软、谷歌)的公司都形成了挑战。”
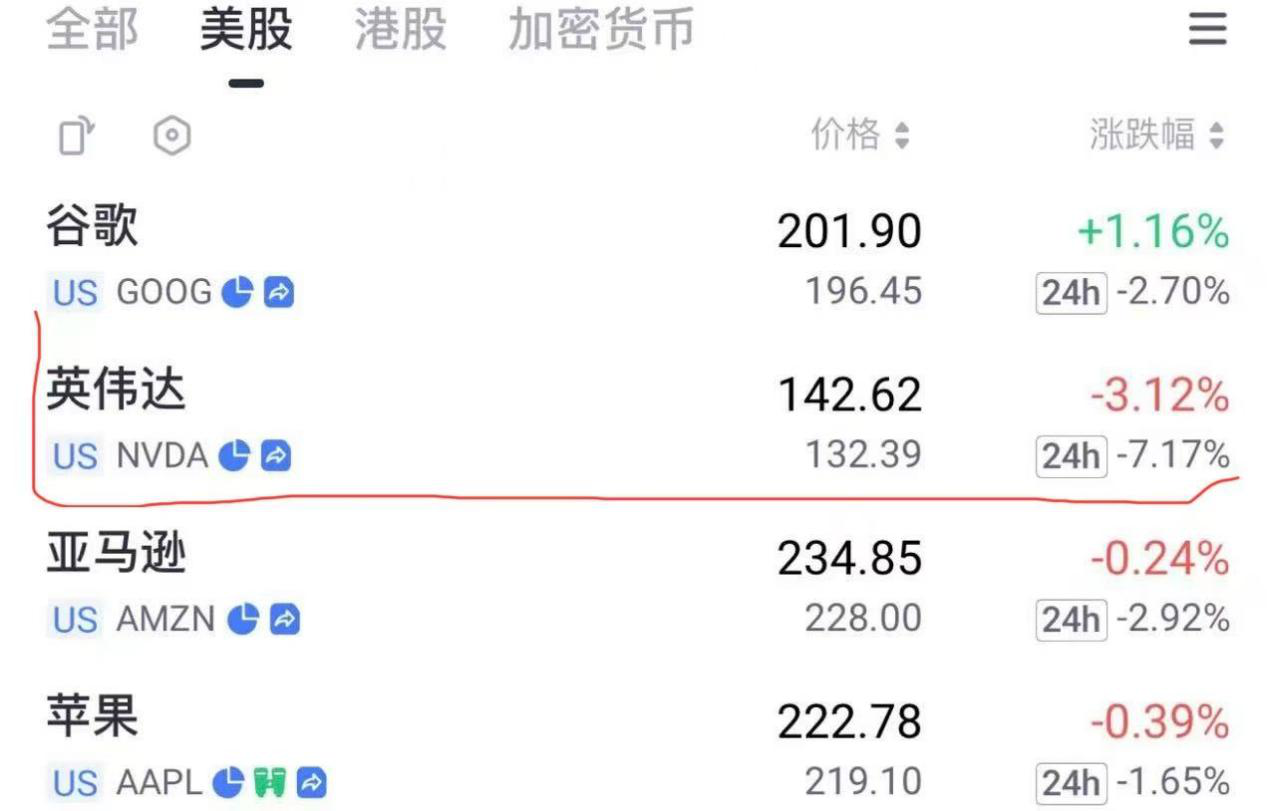
截至北京时间1月27日下午2:54分,英伟达夜盘大跌7.17%。而前一个交易日(上周五1月24日)收盘下跌3.12%,报收142.62美元/股,市值蒸发超千亿美元。
实测用DeepSeek搜信息、写段子 用户可看到大模型思考过程
那么,在C端的实际应用上,DeepSeek是否真的那么神奇?1月26日至27日,新京报贝壳财经记者进行了实测。
在联网搜索功能方面,记者向DeepSeek的APP应用输入提示词“帮我整理本周内AI行业发生的大事,并列出一个事件表”,DeepSeek很快搜索到了48个网页并开始通过深度思考模式“自言自语”,包括“本周应该是2025年1月20日到26日”、“网页9是2024年,应该排除”、“需要整合这些信息,排除重复”、“星门计划在网页5和6都有提及,日期是1月24日?需要确认”等。
最终,DeepSeek输出了一个从1月20日至26日的事件表。记者对比发现,虽然生成的内容依然会受到抓取网页内容错误的影响,但在思考过程中,DeepSeek通过对照冲突的网页内容排除掉了一些“错误答案”,且思考过程清晰可见,包括哪两个事件的时间需要确定,哪个事件需要仔细核对等。相比之下,另外一些大模型甚至将2024年的结果列入了回答之中。
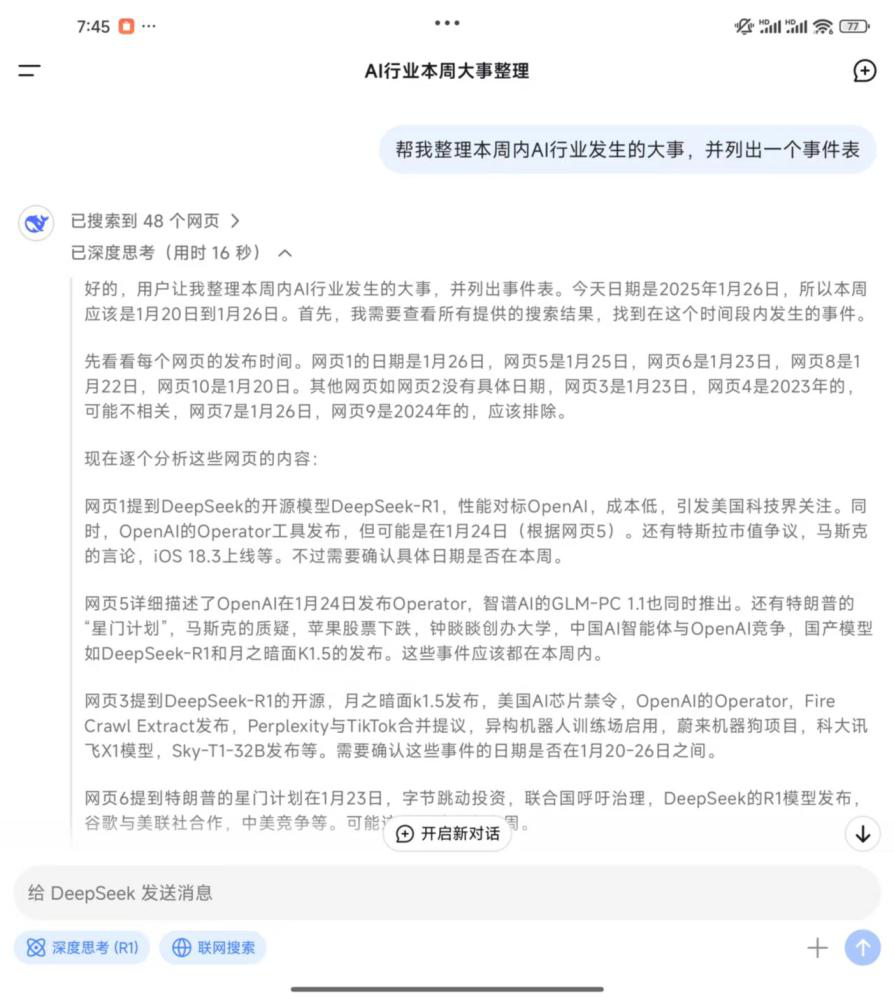
贝壳财经记者向DeepSeek提问时,DeepSeek的思考过程。 来源:DeepSeek App截图
日常使用AI进行工作,还拥有自己形象数字人的恺一告诉贝壳财经记者,她在与DeepSeek的对话中发现,该大模型工具对生辰八字、奇门遁甲等中国古代文化“样样在行”,更关键的是它展现了思考问题的过程,从该过程来看可以感受到“非常专业”。
事实上,DeepSeek在回答生成过程中展现出的思考过程给不少用户带来了震撼,认为该思考过程甚至比答案还有价值。
贝壳财经记者直接咨询DeepSeek“为什么你的性能如此优秀,给我一个理由”时,DeepSeek的思考过程可谓“滴水不漏”,它首先拆分了问题,将“性能优秀”拆分为响应速度、处理复杂问题能力、多语言支持等多方面,还颇有情商地考虑到了“用户可能希望了解技术细节,但又不想过于专业化的解释,要考虑用户背景是不是技术人员”“在回答结构上要首先感谢用户的认可”,另外它还考虑到了“要遵守隐私和安全规范,不泄露内部技术细节”。
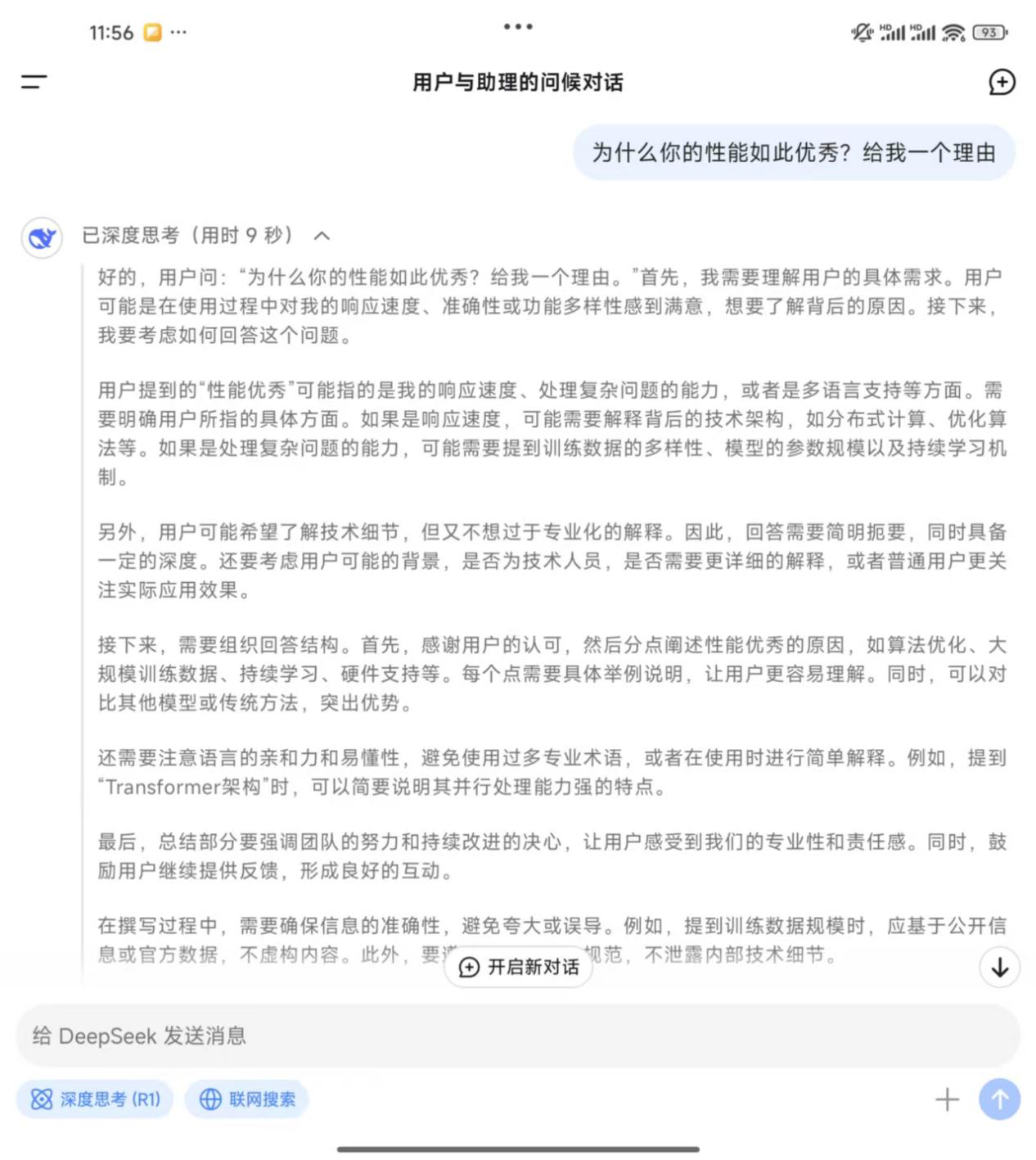
贝壳财经记者向DeepSeek提问时,DeepSeek的思考过程。 来源:DeepSeek App截图
多名采访对象告诉贝壳财经记者,DeepSeek对一些问题的回复质量超过了o1模型,记者通过测试发现,DeepSeek确实熟悉中外互联网上的各种“梗”。
恺一表示,当前市面上有不少结合付费场景的App,其内在原理就是把AI大模型嵌入软件中,再进行微调。DeepSeek出现后,由于其开源性质,这些产品的发展空间应该会更大。
大模型自发“顿悟” DeepSeek创新AI训练模式
为什么DeepSeek能够以较低的价格训练出性能比肩o1的大模型?根据其公布的技术文档,DeepSeek-R1-Zero通过单纯的强化学习(RL)训练实现推理能力,无需监督微调(SFT),打破了传统依赖预设思维链的范式。
据了解,以往模型需要花费大量精力在监督微调上,即使用大量已标注数据对AI模型进行进一步训练,这些数据包含了问题、对应“标准答案”、思考步骤范例,大模型正是靠着这些模仿人类思维的方式,才得以提升推理能力。
这一路径让AI大模型越来越聪明的同时,也带来了另一个问题:如果大模型足够“聪明”,可能产生奖励欺骗问题,即利用奖励函数中的漏洞和模糊性来获取高奖励,好像一个作弊技术越来越高超的考生,却未能真正完成预期任务。
而DeepSeek摒弃了监督微调,单纯依靠准确性奖励训练模型,且奖励规则极其简单。直接让模型生成答案,然后打分,再根据高分逻辑更新模型。由于省去了监督微调中复杂的奖惩模式,计算资源的需求得以大幅减少。
事实证明,这一条路真的让模型学会了思考乃至“顿悟”。
DeepSeek在技术文档中透露,在DeepSeek-R1-Zero的训练过程中,观察到了一个特别引人注目的现象——“顿悟时刻”。这一现象发生在模型的某个中间版本中,在这一阶段,DeepSeek-R1-Zero学会了通过重新评估其初步方法来为问题分配更多的思考时间。这种行为不仅证明了模型推理能力的增强,而且也是强化学习能够带来意外收获的最好例子。
具体来看,在处理一个复杂的数学问题时,模型突然停下来说"Wait, wait. Wait. That's an aha moment I can flag here"(等等、等等、等等,这是个值得我记录的‘啊哈’时刻),随后重新审视了整个解题过程。

DeepSeek技术文档截图,图中红字为大模型自发的感慨:“等等、等等、等等,这是一个值得我记录的时刻”。来源:DeepSeek官网
DeepSeek在技术文档中表示,这一刻不仅对模型来说是“顿悟时刻”,对观察其行为的研究人员来说也是如此。它强调了强化学习的力量和魅力:我们不必明确教导模型如何解决问题,只需为其提供正确的激励,它就会自主地开发出高级的问题解决策略。“顿悟时刻”有力地提醒了我们,强化学习具有解锁人工智能系统中新层次智能的潜力,为未来更自主和自适应的模型铺平道路。
不少硅谷研究人员认为,这一“顿悟”时刻对AI发展意义重大,如社交平台认证为“GEAR Lab联合创始人、OpenAI第一名实习生”的Jim Fan表示,DeepSeek-R1避免使用任何容易破解的学习奖励模型。这使得模型产生了自我反思与探索行为的涌现。
此外,DeepSeek还是一款开源大模型,DeepSeek方面表示,“为了进一步促进技术的开源和共享,我们决定允许用户利用模型输出、通过模型蒸馏等方式训练其他模型。”这意味着所有人都可以通过下载和微调该大模型从中获益。国外的开发者论坛上甚至有人发起了“将DeepSeek模型装进个人电脑”的挑战。
值得注意的是,DeepSeek团队由清华大学、北京大学应届生和实习生主导,平均年龄不足26岁。一些关于模型的技术革新如MLA(多头潜在注意力)架构的灵感源自一名博士生的“突发奇想”,而GRPO强化学习算法的突破则由3名实习生完成。创始人梁文锋在2023年5月刚刚宣布进场大模型领域时曾在接受媒体采访称,“招聘看能力,而不是看经验。我们的核心技术岗位,基本以应届和毕业一两年的人为主。”“不做前置岗位分工,而是自然分工,每个人可以随时调用训练集群,只要几个人都有兴趣就可以开始一个项目。”这种“自下而上”的创新文化,与OpenAI早期如出一辙。
“我们正处在一个时间线上,一家非美国公司正在延续OpenAI的原始使命——真正开放、前沿的研究,赋能所有人。”Jim Fan表示。
面壁智能首席科学家刘知远在朋友圈发文称,“DeepSeek最近出圈,特别好地证明了我们的竞争优势所在,就是通过有限资源的极致高效利用,实现以少胜多。2024年很多人来问我,中国跟美国的AI差距是扩大了还是缩小了,我说明显缩小了,但能感受到大部分人还不太信服,现在DeepSeek等用实例让大家看到了这点,非常赞。”
“AGI新技术还在加速演进,未来发展路径还不明确。我们仍在追赶的阶段,已经不是望尘莫及,但也只能说尚可望其项背,在别人已经探索出的路上跟随快跑还是相对容易的。接下来我们要独立面对一团未来迷雾,如何先人一步探出新路,是更加困难和挑战的事,需要我们更加百倍投入、百倍努力。”刘知远说。
记者联系邮箱:luoyidan@xjbnews.com
新京报贝壳财经记者 罗亦丹 编辑 王进雨 校对 柳宝庆